Hello everybody,
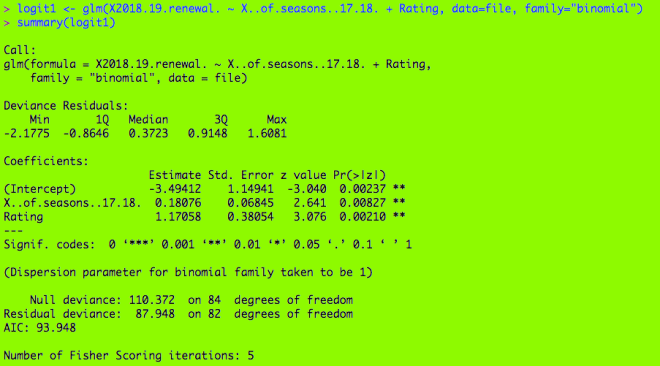
It’s Michael, and today’s post will focus on the WHERE clause in MySQL. For those that don’t know, the WHERE clause basically acts like an IF statement in the sense that it tells the query to only selects rows WHERE certain criteria are met.
OK, so I know I mentioned in MySQL Lesson 4 that the HAVING clause also acts like an if statement. Well, here are some differences between HAVING and WHERE:
- HAVING is used to filter grouped records (think of the queries I posted in MySQL Lesson 4) while WHERE is used to filter individual records
- HAVING always goes with GROUP BY while WHERE never goes with GROUP BY; this is because WHERE does not filter aggregate records while HAVING does.
Now, let’s try out a simple WHERE query

In this query, I selected the fields Singer Name, Age, and Gender from the Singer table. The WHERE Age < 30 line asks the query to select only those singers who are under 30 years old, of which there are 5 (Taylor Swift, Soulja Boy, Lorde, Ariana Grande, and Grace VanderWaal).
Let’s try another WHERE query, this time with a logical operator (more on that below)

In this query, I selected the Ceremony, Won/Nominated fields and the Album_idAlbum foreign key from the Awards table. The WHERE Album_idAlbum = 29 OR Album_idAlbum = 53 line asks the query to only display the results corresponding to awards that albums FK29* OR FK53* were considered for (both FK29 and FK53 are Jay-Z albums, with FK29 being The Blueprint 3 and FK53 being 4:44). As you can see, The Blueprint 3 has two wins out of 3 nominations while 4:44 has 7 nominations.
*FK means having the foreign key, so FK29 means “album with foreign key 29” and FK53 means “album with foreign key 53”
For those wondering what the point of logical operators is, they basically supplement the WHERE clause by setting specific criteria to filter out records. Here are the three most common:
- AND-select records matching (condition 1) AND (condition 2)
- OR-select records matching either (condition 1) OR (condition 2)
- NOT-do not select records matching (condition 1)
You can use all three in the same WHERE statement, just remember that, barring parentheses, NOT will be the first thing read by MySQL, then AND, followed by OR. Portions of the WHERE statement in parentheses are always read first, similar to the order of operations (remember PEMDAS?)
Let’s do another WHERE query, this time working with dates

In this query, I selected the Name and Release Date fields from the Album table. The WHERE MONTH(Release Date) = 12 OR MONTH(Release Date) = 1 OR MONTH(Release Date) = 2 line asks the query to only display the names of albums that were released in the winter months of December, January, or February (represented by 12, 1, and 2, respectively). As you can see, 6 albums meet the criteria
When dealing with dates in a WHERE query, you can either include the whole date (eg. 2011-01-01) or just the YEAR, MONTH, or DAY portion, The correct syntax would be YEAR(field), MONTH(field) or DAY(field), depending on what portion of the date you want to include in your query.
- If you’re dealing with MONTH, remember that months are always represented by the numbers 1-12 (January through December, respectively). Typing in the name of the month usually won’t work for querying.
Sometimes, including the whole date or part of the date won’t make a difference in the results displayed, as shown by these two queries


Each query selects the Name and Release Date fields from the Album table and sorts the results by release date in descending order (starting from the most recently album and then going further back in time). But as you can see, the WHERE line is different for each query. The first query displays WHERE Release Date > 2009-12-31 while the second query displays WHERE YEAR(Release Date) >= 2010. These queries are examples off how including part of the date or the whole date doesn’t make a difference in the output, as both queries select albums released in the 2010s.
- Keep in mind that there are some times that selecting the whole date or part of the date does make a difference in query output.
Now let’s try another WHERE query, this time using string patterns.

In this query, I selected the fields Singer Name and Birthplace from the Singer table. The WHERE Birthplace LIKE '%US' line asks the query only to display the names (and birthplaces) of singers who were born in the US.
You might be wondering what the ‘%US’ means. It basically tells the query to select rows in the Birthplace field that end in ‘US’. Some possible variations of this string pattern include:
- ‘US%’-select all birthplaces that start with ‘US’
- ‘%US%’-select all birthplaces that have ‘US’ anywhere in the name
- ‘_US%’-select all birthplaces that have the letters U and S in the second and third positions, respectively
- ‘US_%_%_%’-select all birthplaces that start with ‘US’ and are at least 4 characters long
- ‘U%S’-select all birthplaces that start with U and end with S
Remember to always use single quotes (‘ ‘) not back-ticks (“) when dealing with string patterns.
One more thing I wanted to note that I mentioned earlier in the differences between the WHERE and HAVING clauses. Now I know I said that the WHERE clause deals with individual records while the HAVING clause deals with grouped records. One thing I did not mention is that the WHERE and HAVING clauses can be used in the same query. Here’s an example:

In this query I selected the field Featured Artist Name from the Featured Artist table. I also added COUNT(Featured Artist Name) in order to display the amount of times each singer appears on the featured artist table. The WHERE Featured Artist Age < 40 line asks the query only to display the names of featured artists under the age of 40. Lines 3-5 of the query group the results by Featured Artist Name and add the additional criteria of only displaying the names of featured artists that appear at least twice on the table (in addition to being under 40 years old); the results are then ordered based on number of appearances (from most to least).
Here are some things you should know about joint WHERE/HAVING queries:
- WHERE always comes before HAVING in a query; this is because WHERE deals with data before it has been aggregated and HAVING deals with data after it has been aggregated
- On a similar note, do not forget the GROUP BY clause in the query, as that must always be included before the HAVING clause
- This is because the data has to be grouped before it can be filtered further
Thanks for reading,
Michael