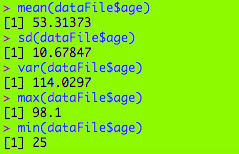
Hello everybody,
This is Michael, and today’s post will be on basic graphing with R. I’ll be using a different dataset for this post-murder_2015_final , which details the change in homicide rates from 2014 to 2015 as well as the individual homicide rates for 2014 and 2015 in 83 US cities (I felt this one was more quantitive than the dataset I used in my last two posts).
So let’s begin with a bar chart.
![]()
- If you can’t read this, here’s the code
- plot(file$X2015_murders, file$change, pch=20, col=”red”, main=”2014-2015 murder rate changes”, xlab=”2015 murders”, ylab=”Change from 2014 homicide rate”)

As you can see, there are two outliers at the upper-right hand corner of the screen. If you want to find out what those cities might be, here’s how you would add labels to each of the points.
![]()
- Remember not to close the window with the graph when typing this command!

From this graph, we can see that the two outliers (or cities with the largest 2014-to-2015 rise in murder rates) are Chicago and Baltimore.
Let’s try a bar graph now. Here’s the command to make a basic bar chart.
![]()

As you can see, 53 of the cities had a year-to-year rise in murder rates, 4 had no change in murder rates, and 26 had a year-to-year drop in murder rates (if you’re wondering what those cities are, check the spreadsheet attached to this post).
Let’s make another graph-the box plot. Here is the command
![]()

Some things to know when reading a box plot
- The bold dashes represent the median value for the murders in a certain state (or only value if a state appears just once)
- The top and bottom lines represent the lowest and highest values corresponding to a certain state
- The yellow bars denote the range of the majority of values for a certain state
- The dashed lines on the top and bottom of the chart show the highest and lowest values not in the range denoted by the yellow bar
- If there aren’t any dashed lines, then the yellow bars denote all of the values, not just the majority
- Any circles you see are outliers corresponding to a particular state.
One more thing, if you’re wondering where I got this data from, here the website-https://github.com/fivethirtyeight/data/blob/master/murder_2016/murder_2015_final.csv. The website is FiveThirtyEight.com, which writes interesting data-driven articles, such as The Lebron James Decision-Making Machine. FiveThirtyEight then posts the code and data used in these articles on GitHub so anyone can perform statistical analyses on the data (good place to look for free datasets for your own data analysis project, and much more interesting than the free datasets that come with R with data 40+ years old).
Thank you,
Michael