Hello everyone,
It’s Michael, and I thought a perfect first post (aside from my welcome post) would be an intro to the wonderful, statistical and completely free software known as R. The dataset I will use will be congress-terms.csv, which I have attached to this post.
To start we will first upload the file onto R. If you are wondering how to do that, here’s the command:
- dataFile <- read.csv(“/Users/michaelorozco-fletcher/Downloads/congress-terms.csv”)
You may choose different a different variable name. Your file path will be different too. To know what your file path is, open up Excel, then click File > Properties. This window will pop up.

The location field would be your file path (along with a slash and the file name, congress-terms.csv in this case, after “Downloads”).
Allright, now that I explained how to read a CSV file onto R, here are some basic R commands.

str(dataFile) displays a summary of all the data fields in the file, which is important for understanding the data you are working with. As mentioned above, there are 18635 observations of 13 variables, which include
- congress-which term of Congress does a particular congressperson serve in (anywhere from the 80th-lasting from 1947 to 1949-to the 113th-lasting from 2013 to 2015)
- chamber-whether a particular congressperson is a part of the House or Senate
- bioguide-each congressperson’s ID Number within the Biographical Directory of the United States Congress
- firstname, middlename, lastname-These are self-explanatory
- suffix-A “Jr.” or “III” or something like that at the end of a particular congressperson’s name
- birthday-Again, self-explanatory
- state-What state the congressperson serves
- party-A congressperson’s party affiliation, whether D for Democrat, R for Republican, I for independent, among others
- incumbent-whether a congressperson was in office at the beginning of a particular term (such as the 110th Congress) or came into office after another congressperson left
- termstart-when a term of Congress began
- age-how old a congressperson was when a term began
Now lets check out some other basic commands. I used the age field because it is the field with the most numbers.
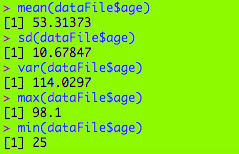
Above you will find the mean, sd (standard deviation-square root of variance), var (variance-the standard deviation squared), max, and min for the age field. Some inferences we can make include
- There is a fair spread among the ages (10.67 years, as given by sd)
- The ages are quite spread out from the 53.31 mean (as given by the 114.03 var)
- The oldest congressperson was almost 100 when his term began (J. Strom Thurmond, 1902-2003)
These are just a few of the basic commands. For more commands check out https://www.calvin.edu/~scofield/courses/m143/materials/RcmdsFromClass.pdf
Here’s the spreadsheet: congress-terms
Thank you,
Michael











