Hello everybody,
It’s Michael here, and today’s lesson will be on cleaning a pandas data-frame (pt.3 in my pandas series).
Analyzing data certainly gives you useful insights on your data-however, most real life datasets don’t look as neat as the datasets we’ve worked with over the course of this blog’s run. Oftentimes, real life datasets can be quite messy, which means you’d need to tidy them up before working with them.
Here’s the messy dataset we’ll be working with in this post:
This datasets contains data regarding 650 employees at a company. And in case you’re wondering, unlike with most of my blog posts, this data doesn’t pertain to anything in real life. I completely made it up.
Now, let’s open up our IDE, import the pandas package, and read our data-frame into our IDE:
import pandas as pd
employees = pd.read_csv('C:/Users/mof39/OneDrive/Documents/Employee data.csv')- Keep in mind that the dataset I’m using and the dataset I provided for you guys have different names-that’s because WordPress doesn’t let me upload CSVs and the
read_csvfunction doesn’t work with XLSX files. The dataset I provided for you guys and the dataset I’m using in this code is the same dataset-just named differently so I can easily distinguish between the CSV and XLSX files.
Great! Now, let’s take a look at the head of our data-frame:

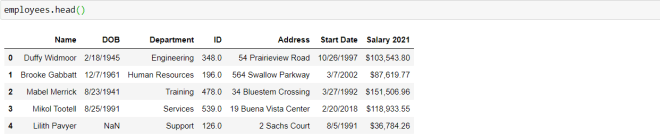
As you can see, our dataset has seven variables. Let’s explore what each variable represents:
Name-The name of the employeeDOB-The employee’s date of birthDepartment-The employee’s department in the companyID-The employee’s employee ID numberAddress-The employee’s home addressStart Date-The date the employee started with the companySalary 2021-The employee’s base (pre-tax) salary for the calendar year 2021.
However, we can’t yet create any visualizations with this data or conduct any meaningful analyses. Here are the things we must clean up first:
- Two employee records are repeated multiple times.
- There are several null records in the
DOBcolumn. - Several records in the
IDcolumn are stored asfloat, notint.
First, let’s take care of the null records in the DOB column. When dealing with null/blank records in a data-frame, there are two ways you can deal with this issue:
- Remove the rows with null values from the dataset.
- Replace the null values with a specific value or the mean/median/mode of the values in the column.
Well, since the null records are found in a date column, replacing the nulls with the mean/median/mode won’t work here. We could replace the null records in the DOB column with something like 1/1/2021 or we could remove the rows with null records altogether.
In this case, let’s remove the null records altogether. Here’s the code to do so:
employees.dropna(inplace=True)You will only need a single line of code with the dropna() function in order to drop all null rows from the dataset. Now, you’re probably wondering what inplace=True means-this line of code signifies that you want to drop all null rows from your current data-frame. If you don’t include this line of code, a new data-frame with the null rows removed will be created-your current data-frame (employees) won’t be changed at all.
Now, let’s see what the dataset looks like without the null rows:

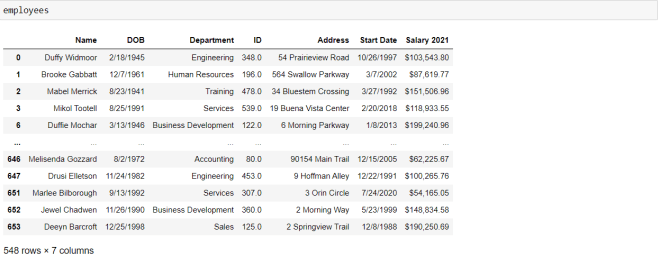
As you can see, there are now 548 rows in the dataset (there were 654 rows before we removed the null records).
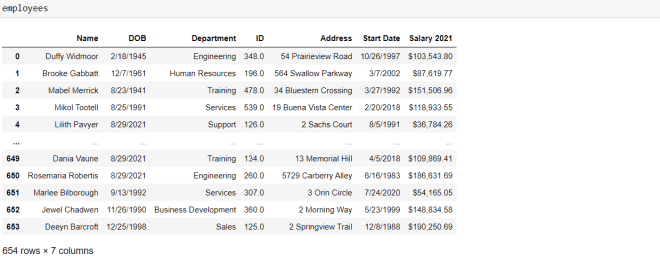
But what if you didn’t want to remove all the records with null birthdates? What if you simply wanted to fill all null DOB records with a placeholder date-let’s say 8/29/2021. Here’s the code you’d need to run:
employees["DOB"].fillna("8/29/2021", inplace=True)To replace all the null values in a certain column with a placeholder value, use the fillna() function with two parameters-the value you’d want to use to replace the null values and the inplace=True line. The inplace=True line works the same way here as it does with the dropna() function.
Another thing to note is that if you only want to replace the null values in a specific column, you’d need to specify that column before the fillna() function. If you don’t do this, ALL null values in the data-frame will be replaced, which isn’t ideal since the values in each column of your data-frame are usually of different data types.

Now, the second bit of cleaning we’d need to do is to change the ID values to type int-they are currently of type float. Here’s the code we’d use to change the data type of values in a pandas data-frame column:
employees["ID"] = pd.to_numeric(employees["ID"], downcast="integer")To change the data type of the values in the ID column from floats to integers, use the to_numeric() function and pass in two parameters-the column that you want to format (employees["ID"]) in this case and downcast=integer. The reason for the downcast=integer line is to ensure all of the values in the ID column will be converted into integers. Had we not included this line, the data type of the values in the ID column would’ve still been floats.
Now, let’s see what the table looks like after this modification:

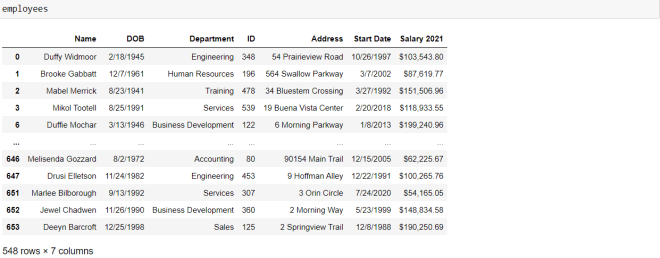
As you can see, all of the values of the ID column are now integers.
- Note, this is what the data-frame looks like after I dropped the null
DOBvalues, not after I filled the nullDOBvalues with8/29/2021.
Last but not least, I mentioned that two employees’ records are duplicated. Let’s see how we can remove duplicate values from a data-frame:
employees.drop_duplicates(inplace=True)
To remove the duplicates from the data-frame, simply use the drop_duplicates() function and pass in the parameter inplace=True.
Last but not least, let’s export our cleaned data-frame to a CSV file. Here’s the code to do so:
employees.to_csv('C:/Users/mof39/OneDrive/Documents/Employee data cleaned.csv')After specifying the data-frame you want to export, use the to_csv() function to export the data-frame. You’ll need to pass in 1 parameter-the location on your computer where you want to store the cleaned data frame. It’s that simple.
Thanks for reading,
Michael












