Hello everybody,
Michael here, and for today’s post, I’ll discuss something a little different-neural networks; this is the first post of my new AI (artificial intelligence) series. Granted, I’ll be using Python, which I’ve used quite a bit in this blog (this is my 37th Python lesson after all).
More specifically, in today’s post, I will be discussing the basics of neural networks and how to set up a simple neural network in Python. And in case you’re wondering (and/or really enjoy AI content), the remainder of my 2022 blog posts AND my first few 2023 posts will cover neural networks.
But first, a little bit about machine learning…
For those of you who’ve been following my blog for quite a while, you may recall that a lot of my earlier entries covered machine learning.
But what is machine learning exactly? It’s essentially a process where you are training a program to do something (like identifying a certain plant from a photo)-or in better terms, training a machine to learn something (hence the term machine learning). One of my early posts from February 2019-R Lesson 10: Intro to Machine Learning-Supervised and Unsupervised-does a good job of explaining some of the basics of machine learning. Granted, I wrote this post as part of a series of R lessons, but the gist of the post can be applied to any programming/automation tool.
Now onto neural networks
What is a neural network (in the context of programming)? To help explain this concept, think of the way all of the neurons in your brain process information. Neural networks operate in a similar manner, as they are meant to process information via a computer program that’s meant to mimic the way our brains process information.
Neural networks are a form of machine learning, and just like machine learning, you can utilize supervised and unsupervised machine learning with neural networks. Unsupervised machine learning with neural networks actually has a name of its own-deep learning, which is a process you use to allow the neural network to train itself rather than coding in any guidance for the neural network’s operation.
A neural network you’ve likely come across
A neural network you’ve most likely seen or heard of before is deepfakes. If you’ve ever seen a video where it appears someone’s face looks stitched onto someone else’s body-that’s deepfake AI at work.
A great example of deepfake AI at work was seen on season 17 (2022) of America’s Got Talent–https://www.youtube.com/watch?v=Jr8yEgu7sHU&t=116s. The act in the linked video-Metaphysic-utilized deepfake AI to make it appear as if the king of rock’n’roll Elvis and judges Sofia Vergara and Heidi Klum were singing Elvis’s greatest hits. Take a closer look at the video, and you realize that “Elvis”, “Sofia”, and “Heidi” are being animated by three singers in real-time standing in front of projectors. Pretty neat stuff, right? Plus, Metaphysic finished the season in 4th place-not too shabby for AGT’s first deepfake/metaverse AI act.
Another brilliant, albeit controversial, example of deepfake AI at work can be found in Kendrick Lamar’s 2022 music video for The Heart Part 5–https://www.youtube.com/watch?v=uAPUkgeiFVY (highly recommend listening to Mr. Morale & the Big Steppers). In this video, Kendrick Lamar uses deepfake AI to transform himself into six notable celebrities-OJ Simpson, Kanye West, Jussie Smollett, Will Smith, Kobe Bryant, and Nipsey Hussle-while rapping six different verses from the perspectives of these individuals.
Did I cover neural networks before?
Did I ever explicitly cover neural networks before? No.
However, several past posts did cover machine learning-both supervised and unsupervised. Here are a few of those posts:
- R Lesson 13: Naive Bayes Classification-(from April 2019) in this post, we use R to perform spam detection on a dataset of YouTube comments from Eminem’s Love The Way You Lie music video using the Naive Bayes classification algorithm
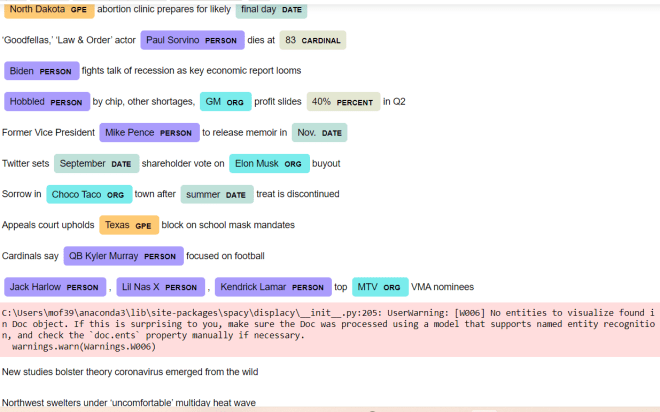
- Python Lesson 36: Named Entity Recognition (NLP pt. 5)-(from August 2022) in this post, we use Python NLP (natural language processing) to detect named entities in a string of text
- R Analysis 9: ANOVA, K-Means Clustering & COVID-19-(from April 2020) in this post, we use R to perform ANOVA analysis and k-means clustering on data regarding the COVID-19 pandemic (case counts, lockdowns, etc.)
Thanks for reading,
Michael